
The Model Interface Edge Weekly — Issue 10
Week of Apr 25-May 8

Issue 10 · Two weeks of April 25 – May 8, 2026
🚀 New Models
Deep Dive: Poolside Open-Sources Laguna XS.2 (33B-A3B Apache 2.0 Coding Model on a 36 GB Mac)
Poolside Blog · VentureBeat · HF

33B total / 3B active MoE for agentic coding. Sliding-window plus global attention 3:1 across 40 layers, 256+1 experts, sigmoid gating, 131,072 context. Headline scores: 68.2% SWE-bench Verified, 62.4% Multilingual, 44.5% Pro, 30.1% Terminal-Bench 2.0. Memory footprint: roughly 36 GB RAM on a 36 GB Apple Silicon Mac via Ollama + MLX, with day-one packaging. Apache 2.0.
The "who shipped it" is the story. Poolside was founded by Jason Warner (former GitHub CTO) and Eiso Kant on the premise that proprietary frontier coding models would be the moat, and raised a nine-figure round into 2024 on that thesis. Until now they were closed-API only. Laguna XS.2 is their first weights drop, and the model competes with Cursor's hosted backends at a tier that fits in a single laptop's RAM.
Competitive dynamics. 68.2% SWE-bench Verified is in the same band as the hosted backends Cursor and Codex rely on, which means the value proposition of "subscribe for the best coding model" gets tougher when the second-best model is free, Apache-licensed, and runs without a network call. The local-coding stack (Continue.dev, Aider, Roo Cline, Zed Assistant) just gained a frontier-class backend, and we can clearly see that the open vs closed competition is heating up with Open Source models quickly catching up to the close source competitors.
Funding & strategy. A lab that raised on a closed-weights thesis shipping weights is the signal worth reading. The most plausible read: Poolside is shifting where the moat lives, away from "we have the only model" and toward services, enterprise deployment, fine-tuning, and tooling. The same pattern Mistral ran in 2024 and Databricks/DBRX ran before that.
Enterprise adoption & licensing. Apache 2.0 is the cleanest license possible. No usage caps, no commercial restrictions, no IP review gates, no telemetry. This follows the release of the Gemma 4, Qwen models with similar licensing. Enterprise legal teams that block OpenRail-licensed and "research-only" weights will green-light Laguna XS.2 without an audit cycle. Compared to NVIDIA's Open Model Agreement or Meta's Llama Community License, this is the lowest-friction frontier-class coding model available for commercial deployment.
Pricing & unit economics. Cursor's individual plan runs $20/month, business $40/seat/month; Codex API usage on a heavy agentic workflow can clear several hundred a month. A 36 GB M3 Pro Mac (~$2,499 one-time) hits break-even against a single Cursor seat inside two years, against a heavy API user inside one. For a 10-engineer team on Cursor Business, the break-even on local hardware is roughly six months. The economics don't kill hosted coding tools, but they do reframe the buy decision.
Local stacks. Day-one Ollama + MLX packaging means anyone on an M3 Pro or better can ollama pull poolside/laguna-xs.2 and have it running tonight. The 33B-A3B sparsity profile is the same architecture pattern mlx-vlm and llama.cpp have been optimizing for the last quarter, so the throughput should be competitive on Apple Silicon out of the gate, with an llama.cpp port expected shortly.
Agent / IDE integration surface. Cursor-class agentic coding without a hosted endpoint changes what's possible inside the IDE. Continue.dev with a local Laguna XS.2 backend is a credible Cursor alternative for individual developers today. The Pi harness, Aider, and Roo Cline all gain a stronger local backbone, which compounds with antirez's DS4 work on DeepSeek V4 Flash to make the "no cloud at all" agentic-coding loop suddenly real.
Open-weights momentum. Coding-specific frontier is now mostly open: Qwen3-Coder, DeepSeek-Coder V4, Devstral, IBM Granite Code, now Poolside. The closed-API coding labs (Anthropic, OpenAI, Cursor) are the holdouts, and the gap between best-closed and best-open at SWE-bench has compressed inside one quarter. Worth watching whether Cursor responds by releasing its own training-from-scratch model open, or doubles down on hosted-only differentiation.
Hardware tier accessibility. Six months ago a Cursor-class local backend needed 80 GB+ of unified memory or a 4090. Laguna XS.2 puts it at 36 GB Mac, which is the most common configuration on developer desks today. The floor for "frontier coding on a laptop" just dropped from workstation to mainstream, following the other recent open model releases.
Deep Dive: NVIDIA Nemotron 3 Nano Omni (30B-A3B Multimodal, 18 GB at NVFP4)
HF Blog · NVIDIA Developer · SiliconANGLE

30B total / 3B active hybrid Mamba-Transformer MoE. C-RADIOv4-H vision encoder + Parakeet-TDT-0.6B-v2 audio encoder. Text, image, audio, video, document, and screen modalities in; text out. 256K context window, 20-minute audio segments, 100-page documents. The NVFP4 build comes in at 18 GB, which means it runs on a 24 GB consumer GPU. Day-one Ollama support; day-one mlx-vlm support on Apple Silicon. Unsloth showed it running in ~25 GB of RAM. License: NVIDIA Open Model Agreement (commercial use permitted with terms).
NVIDIA's Nemotron line is an ecosystem play, not a revenue product. NVIDIA doesn't need open weights to sell GPUs, but it does need a flagship open-weights model that's clearly best-on-NVIDIA to anchor the developer community to its stack. Nemotron 3 Nano Omni is the highest-effort version of that strategy to date: full multimodal, sized for a single consumer card at NVFP4, and shipped with the entire NVIDIA inference stack lit up on day one.
Competitive dynamics. Nemotron is the that pulls audio (20 min), video, document (100-page), and screen modalities into one set of weights at a consumer-GPU footprint. Against closed-API competitors (GPT-4o-mini multimodal, Gemini Flash), the comparison shifts from "quality gap" to "what's worth running on-device for latency and cost."
Funding & strategy. NVIDIA's interest in open weights is moat extension, not moat building. Every download of Nemotron 3 Nano Omni that runs well on NVFP4 builds switching cost into Blackwell-class silicon. Every developer who learns the Nividia Inference stack via a free open-weights model is a developer harder to lose to AMD ROCm or Apple Silicon. The cadence and capability of recent Nemotron releases suggests this strategy is escalating.
Enterprise adoption & licensing. The NVIDIA Open Model Agreement allows commercial use, but it isn't Apache 2.0. Common gotchas in past versions: restrictions on using outputs to train competing models, indemnity carve-outs, and notification obligations for redistribution. Enterprise legal teams will not block adoption, but they will read the agreement, and most will treat it as a "deploy, don't redistribute" license. Cleaner than research-only weights; less clean than Gemma’s or Poolside's Apache 2.0.
Pricing & unit economics. Audio transcription + screen analysis + 100-page document QA in one model at no per-token cost is the cost story. A heavy agentic workflow on GPT-4o or Gemini Flash multimodal API can run several hundred dollars a month per power user; Nemotron 3 Nano Omni on a single $1,599 RTX 5080 or 24 GB 4090 amortizes against API spend in weeks, not months, for workloads dominated by audio and document ingestion. “Computer Use” agent pattern becomes economically viable especially at scale.
Local stacks. NVFP4 at 18 GB on a 24 GB consumer card is the headline plumbing. Day-one Ollama support means ollama pull nvidia/nemotron-3-nano-omni works today. Day-one mlx-vlm support means it also runs on Apple Silicon despite being a NVIDIA-flagship release. Unsloth confirmed 25 GB of consumer RAM is enough. The full stack (TRT-LLM on NVIDIA, mlx-vlm on Apple, llama.cpp on either) is lit up, which is exactly the cross-vendor coverage that drives adoption.
Agent / IDE integration surface. Three of the highest-value agent patterns sit in one set of weights: a screen-watcher that sees what you're doing, a meeting transcriber that handles 20 minutes of audio in a single pass, and a document-QA agent that ingests 100-page PDFs end to end. Running all three off the same local model means one warm cache, one prompt cache, one set of fine-tunes, and one inference daemon. The plumbing simplification is as valuable as the capability.
Open-weights momentum. NVIDIA is shipping more capable open weights more frequently. Multimodal-native at the open-weights frontier is now table stakes; the next 6-12 months of open releases will be expected to handle vision, audio, and screen as a baseline. Closed-API multimodal labs (OpenAI's GPT-4o-mini, Google's Gemini Flash) face the same pressure on multimodal that Poolside is applying on coding: a free, locally-runnable alternative reaches "good enough" for the long tail.
Hardware tier accessibility. Six months ago, running an omni model meant a server with 80 GB+ HBM or a multi-GPU rig. Nemotron 3 Nano Omni runs on a $1,599 RTX 5080, a 24 GB RTX 4090, or a 36 GB Apple Silicon Mac.
Deep Dive: Gemma 4 MTP Drafter Goes Live — 2x Speedup on Gemma 4 31B Coding, Apple Silicon Day One
 drafter speed ups")
Multi-token prediction (MTP) trains a model with parallel heads that each predict a token at an increasing future offset (typically +1, +2, +3, +4). Used as a drafter for speculative decoding, the same model generates a multi-token draft in a single forward pass, retiring the standard “small drafter + large verifier” setup. Gemma 4 31B-coding ships with MTP heads trained natively into the model. Ollama v0.23.1 (May 5) and mlx-vlm v0.5.0 are the first mainstream local runtimes to wire those heads up, delivering >2x decode speedup on Apple Silicon via ollama run gemma4:31b-coding-mtp-bf16. Apple ML Research published a parallel M5 Neural Accelerator MLX deep-dive on the same technique.
Gemma 4 itself dropped April 2 with the MTP heads dormant, present in the weights but not exposed by any local runner. The May 5 Ollama release is the moment those heads went from a research artifact to a runtime feature on hardware developers actually own. The MTP-as-drafter pattern was first popularized by Meta’s 2024 paper; Gemma 4 is the first major open-weights release that bakes it in by default.
MedGemma 1.5
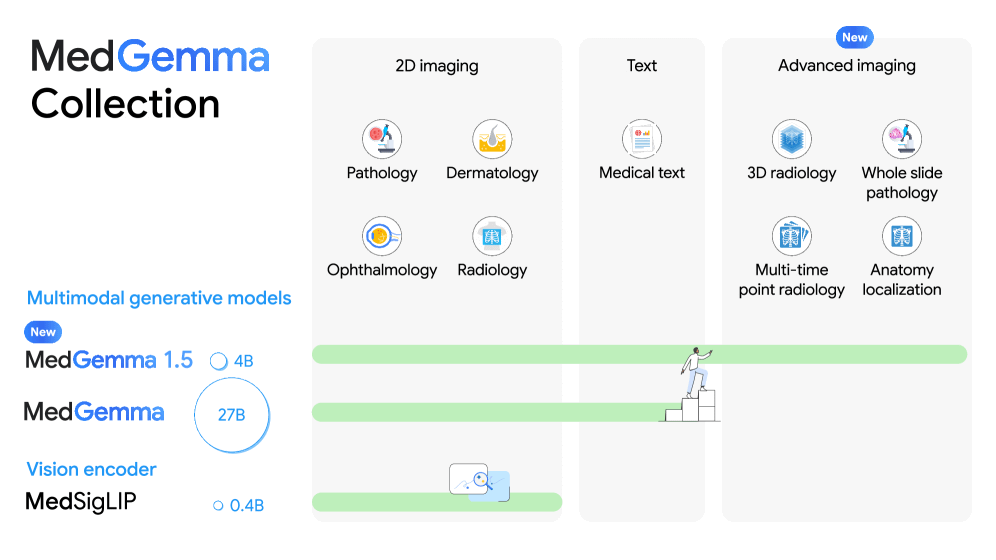
Open-weights medical model in the Gemma family. Adds 3D imaging, pathology slides, and longitudinal multi-timepoint analysis on top of MedGemma 1; accuracy improvements on medical text and image benchmarks. Quantizes and deploys locally the same way Gemma 3 does, which makes on-device pathology readers and hospital-network-resident document QA a near-term option. The most credible open-weights medical model release of 2026.
📄 Papers
AHASD: Asynchronous Mobile NPU+PIM Speculative Decoding (DAC 2026)
arXiv 2604.25326 · ICT, Chinese Academy of Sciences · April 28
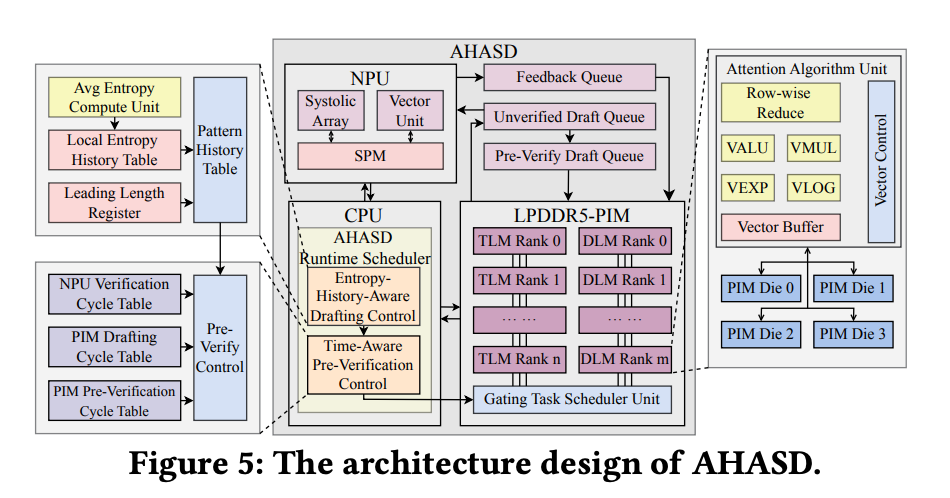
Decouples drafter (PIM) from target (NPU) at the task level so PIM keeps drafting while NPU verifies the previous batch, plus an entropy-aware draft-length controller. Up to 4.2x throughput and 5.6x energy efficiency over a GPU baseline, 1.5x throughput over SpecPIM, with under 3% DRAM-area overhead. Simulator only — Coral-NPU + LPDDR5-PIM, no real silicon, fixed to LLaMA2 family.
Why it matters: Mobile speculative decoding is the path most phone vendors have settled on. AHASD attacks the scheduling glue between heterogeneous compute units — the new bottleneck — and the pattern composes with existing drafter/target pairs without retraining.
Qwen-Scope: SAE Suite Turns Sparse Features into Dev Tools
Qwen Blog · PDF · [HF SAE-Res-](https://huggingface.co/Qwen) · MarkTechPost*
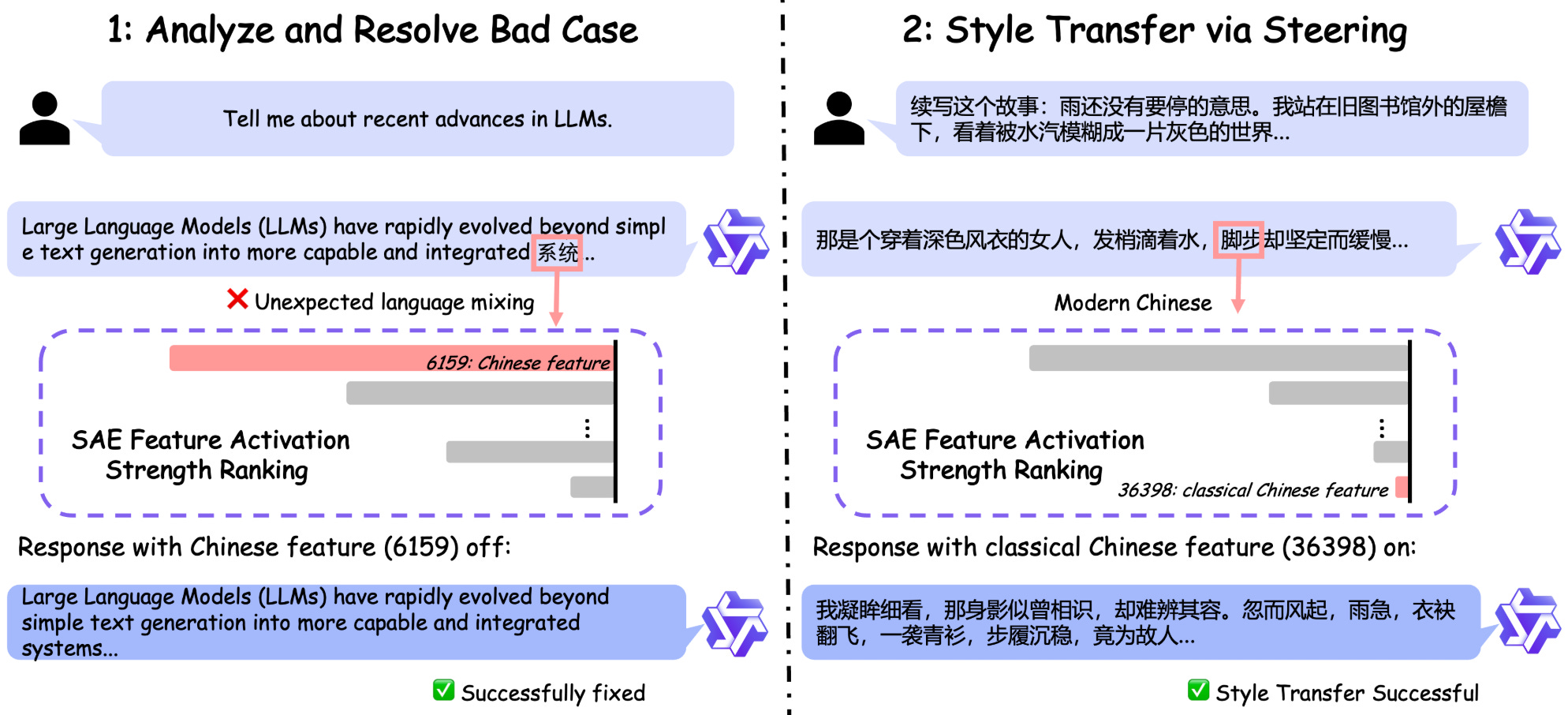
Open SAE drop spanning 14 SAE groups across 7 Qwen variants (Qwen3 1.7B/8B, Qwen3.5 2B/9B/27B, two MoE bases). TopK k=50, residual-stream hooked, dictionaries up to 81,920 features. Headline demo: an OR-rule over a few SAE features hits F1 > 0.90 for multilingual toxicity classification with no training. Code-switching and doom-loop repetition are mitigated by silencing single features at inference time.
Why it matters: First open SAE drop trained natively on a frontier open-weights family, at sizes that actually run on phones and laptops (1.7B, 2B, 8B). Steering small open models is the missing piece between "I have a 1.7B running locally" and "I have a 1.7B behaving the way my product needs."
Anthropic: Natural Language Autoencoders
Anthropic · May 8
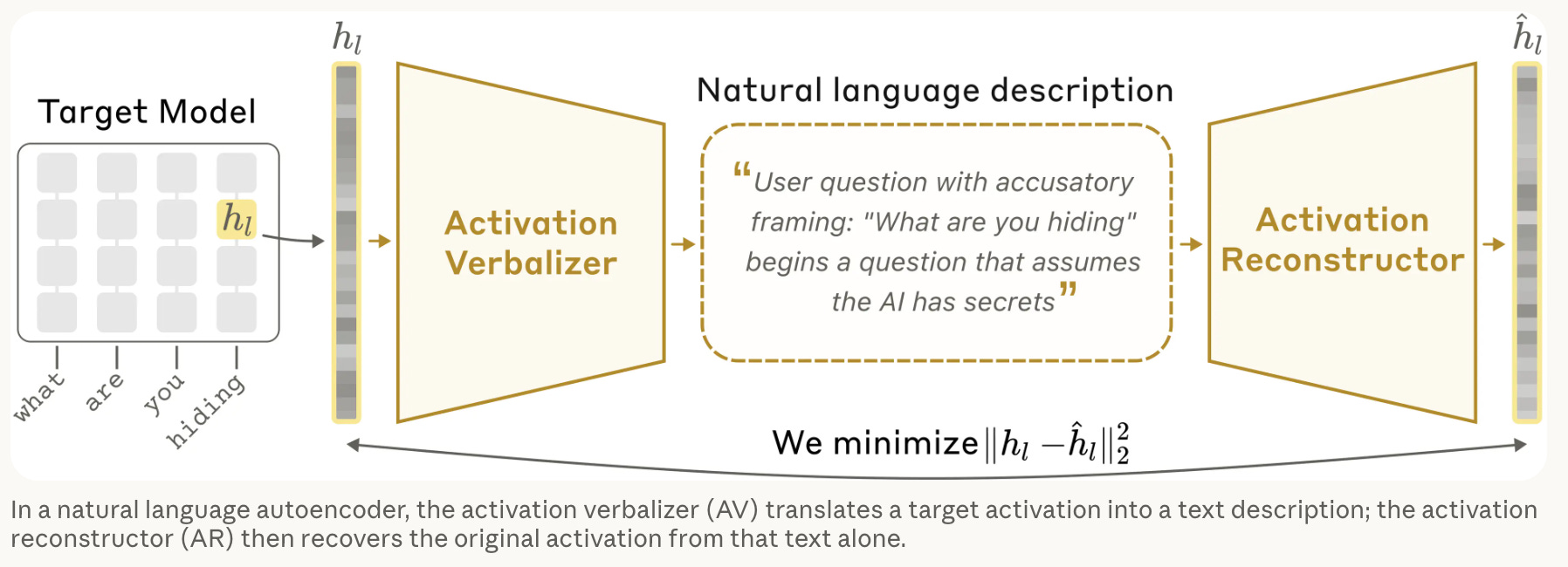
Encoder maps an activation to a short English description; decoder reconstructs the activation from that description. Trained for reconstruction, not clarity, but the descriptions surface useful semantic features and inferred user traits. Aligns reasonably with SAEs but occasionally produces false claims; no released codebase yet.
Why it matters: Natural pair to Qwen-Scope. Where Qwen-Scope ships steering knobs, NLA generates English explanations of activations. Interpretability work will be important to help steer and align the models and build trust with LLMs. This is a step in the right direction.
🎤 Long Reads of the Fortnight
Liquid AI's Maxime Labonne: Everything I Learned Training Frontier Small Models
YouTube · Slides · Speaker bio
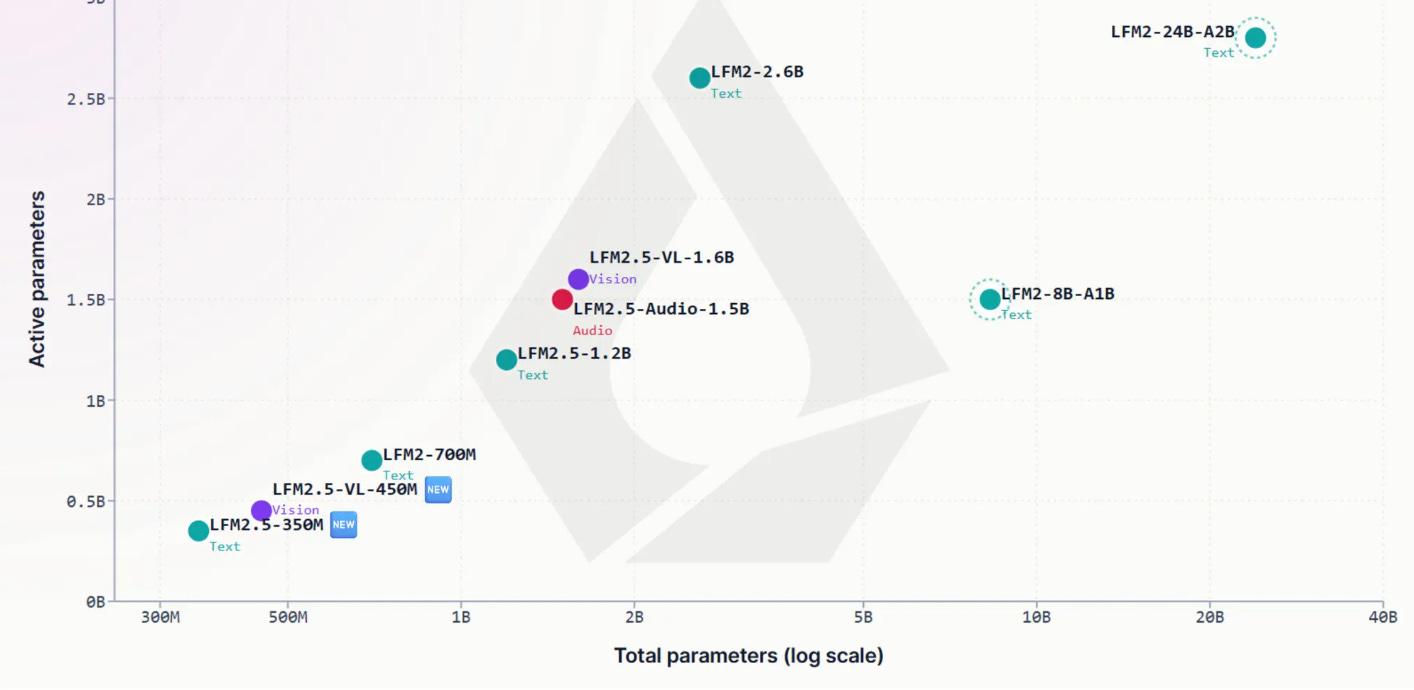
The framing line: "edge models are not just scaled-down versions of bigger models." Walks the LFM2.5-350M / LFM2.5-1.2B-Thinking stack. Operator cost profiled on Galaxy S24 Ultra, Ryzen AI HX 370, M4 Max — ShortConv + GQA on 16 layers wins on M4 decode. Post-training is four stages on a 28T-token base: SFT, preference alignment, on-policy DPO with jury validation, RL with an n-gram repetition penalty (the "doom-loop" fix).
Why it matters: ne of the few public writeups that walks the full SLM training stack which is not based on distillation and also what to optimize for on real edge silicon, why post-training matters more than at frontier scale, and what the failure modes look like in production. Doom-loop framing hands off cleanly to Qwen-Scope steering.
Will Brown: On SFT, RL, and On-Policy Distillation
Tweet thread (1,855 likes) · Claude Artifact (rendered) · Markdown
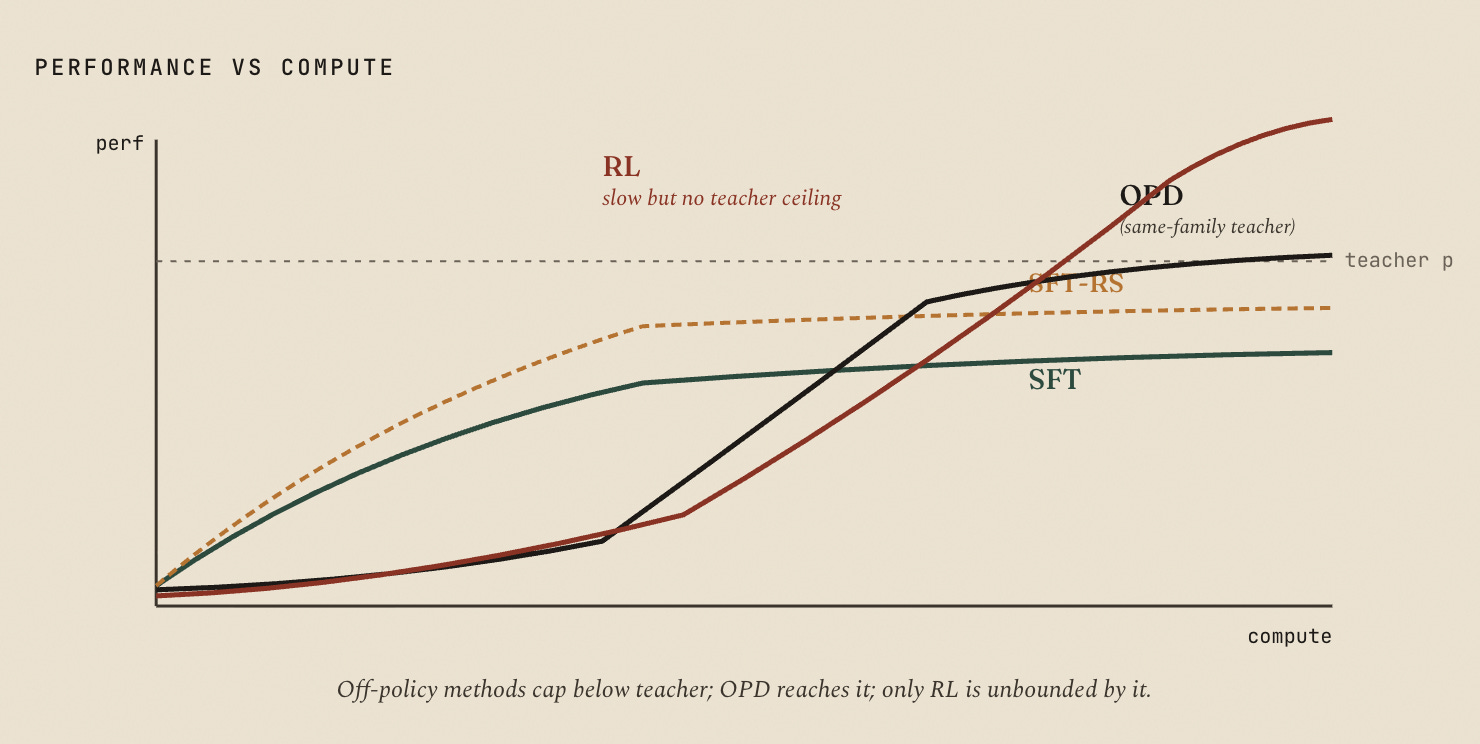
Will Brown (with Claude Opus 4.7) on why SFT-then-RL works, where on-policy distillation fits, and how self-distillation goes wrong. Same-family OPD (Qwen3-32B → Qwen3-8B-Base) reaches RL-equivalent results at 9–30x less compute on AIME-style benchmarks because per-token reverse-KL is dense and on-policy. Cross-family pays a tokenizer-mismatch tax that eats most of the bits.
Why it matters: Cleanest public explainer of the post-training stack that produces shippable SLMs. Lines up with the Qwen3 tech report, Liquid’s LFM2.5 pipeline, and the Ramp 3B-beats-Opus result below.
Meta RAM: Autodata, the Automatic Data Scientist
FAIR/RAM blog · saved via Readwise May 5
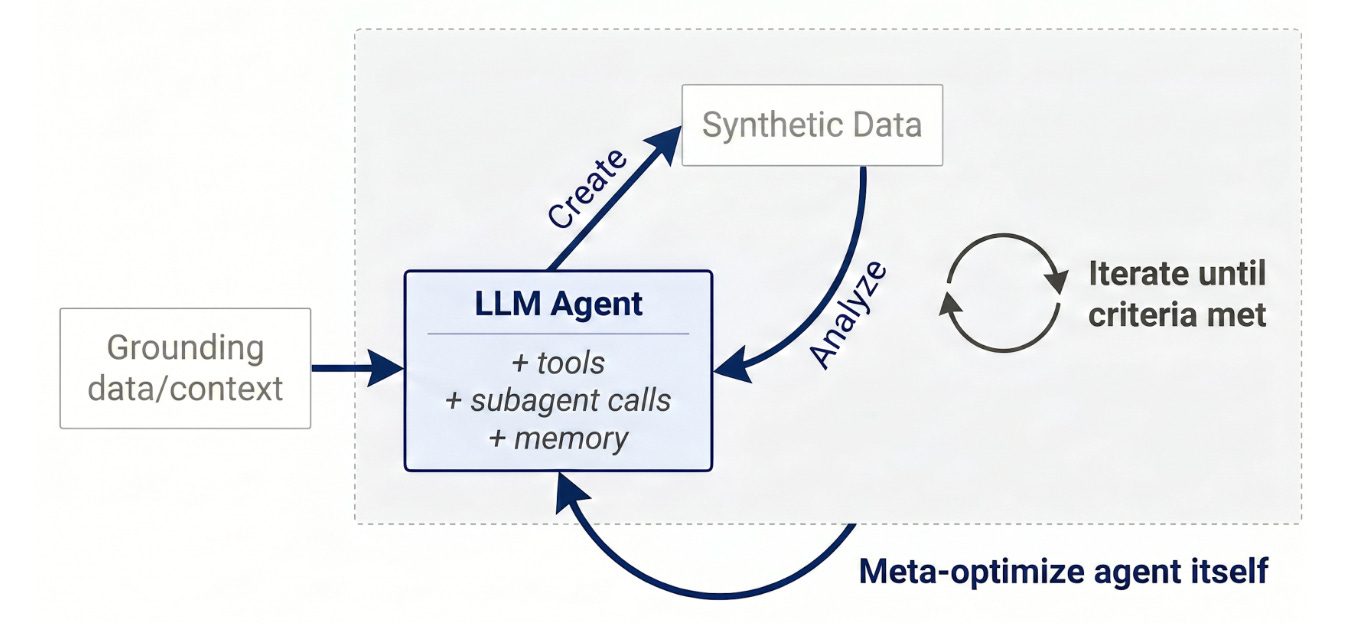
Multi-agent system that generates and filters synthetic training data through repeated create-then-evaluate cycles. Agents collaborate to surface challenging examples that improve weaker student models; the system meta-optimizes its own data quality.
Why it matters: The post-training-data bottleneck made mechanical. Structured data generation is the biggest bottleneck. I am a firm believer that there is an automated solution that can potential solve this problem. I have been experimenting with it on Pinchbench benchmarks here. This paper takes it further with a more formal setup. I will prototype this approach soon, I am almost certain that it would be able to beat my current simplistic approach.
📱 Smart Devices & Wearables
Meta Q1 2026: Ray-Ban Smart Glasses Daily Users Tripled YoY
CNBC · Earnings transcript · Android Central
Q1 revenue $56.31B (up 33%, fastest since 2021). Reality Labs lost $4.028B as AI-glasses spend ramped. Zuckerberg: "the number of people using them daily is tripling year over year." Sales shifting from original Ray-Ban Meta to Gen 2; Ray-Ban Meta Display + Neural Band drawing strong consumer interest.
Why it matters: Tripling DAU (not units) is the first hard signal AI glasses crossed the engagement bar that Humane, Rabbit, and Limitless all failed at. Sets the bar for every other glasses team in the next 12 months.
Apple Q2 2026: Record $111B, Mac Demand Driven by Local AI Workloads
Q2 revenue $111.2B (up 17%, March-quarter record). iPhone $57B (up 22%), Mac $8.4B with Mac mini and Mac Studio supply constrained by developers running local AI workloads. Cook reiterated John Ternus takes CEO Sept 1; Apple Intelligence + Gemini-Siri on track for iOS 27 / iPhone 18.
Why it matters: Apple sits on the world's largest installed NPU base. Two quarterly signals: Mac demand specifically driven by local-AI developers, and AI spend explicitly additive to (not displacing) the hardware roadmap.
Qualcomm Q2 FY2026: Stock +16%, Every Line Reframed Around "Agentic AI"
CNBC · Transcript · Investor release
Q2 revenue $10.6B, non-GAAP EPS $2.65 (high end). Auto record above $5B annualized, exiting FY2026 above $6B run-rate. Snapdragon X2 PC platform now in production (Lenovo Yoga Slim 7x, IdeaPad 5x Copilot+ shipping). Hyperscaler custom-silicon deal shipping by end of 2026. Stock +16% intraday.
Why it matters: First quarter where the X2 PC ramp is real revenue. Amon framing every line around "agentic AI" is the clearest statement that Qualcomm wants to own the silicon layer for on-device agents the way Nvidia owns the data center.
Rokid AI Glasses Style Lands in Europe at $299 with a Model Picker
GlobeNewswire · Korea Herald · Basic Tutorials
Display-free, voice-first, 38.5 g, $299, 12 h battery, 12MP Sony camera. Differentiator: a model picker baked into the firmware (ChatGPT, DeepSeek, Qwen, or Microsoft AI Translation). Translation across 89 languages; prescription support to ±15 diopters.
Why it matters: First shipping consumer device that takes "BYO model" seriously at the firmware layer. Affordable, model-agnostic positioning as the AI glasses category moves from one-vendor to multi-vendor competition. Apple will likely be taking a look at their stack.
🐦 Social Signals
Stanford CS336 — 90% of LLM architecture has converged
@gosailglobal · 3,072 likes · May 5
Threaded summary of Tatsunori Hashimoto's CS336 lecture. The 2026 standard SLM template: pre-norm with LN moved out of the residual, RMSNorm replacing LayerNorm (0.17% FLOPs but 25% wall-clock savings — bottleneck is data movement, not compute), no biases, SwiGLU/GeGLU, RoPE, serial Transformer blocks. Exactly why open SLMs (Qwen3.5, Gemma 3, LFM2.5) can be trained on standardized recipes and shipped to phones without per-architecture re-tuning.
antirez ships DS4
@antirez · 1,010 likes · May 7
"Welcome to DS4, a specialized inference engine for DeepSeek v4 Flash. This project would have been impossible without llama.cpp and GGML and the work of @ggerganov." The hero artifact of the fortnight.
alexstauffer: a 3B with RL beats Opus on spreadsheet retrieval
@alexstauffer_ · 1,101 likes · May 7
"If a piece of your agent loop is narrow, verifiable, and highly repeatable, a tiny trained model might beat the frontier. Cheap domain specialists orchestrated by a frontier model that only spends tokens on judgment is a bet worth watching." Cleanest one-line edge AI thesis of the fortnight, quoting Ramp Labs' Prime-RL post.
simonw: VibeVoice runs 1 hour of audio in 9 minutes on a MacBook
@simonw · 1,014 likes · April 27
"Microsoft's MIT licensed VibeVoice speech-to-text (think Whisper with speaker diarization) is really good. 5.71GB 4bit MLX conversion on an M5 MacBook, ~60GB RAM peak, 1hr audio in ~9 mins." The local-AI thesis written in a single benchmark.
Unsloth: Nemotron 3 Nano Omni runs in ~25 GB of RAM
@UnslothAI · 938 likes · April 28
"Nemotron-3-Nano-Omni-30B-A3B is the strongest omni model for its size and supports audio, video, image and text. Run on ~25GB RAM." Community confirmation of the Nemotron deep-dive above.
Unsloth + NVIDIA: 25% faster home-GPU LLM training
@UnslothAI · 916 likes · May 6
Joint write-up on three optimizations bringing big-rig training tricks to a single home GPU: packed-sequence metadata caching, double-buffered checkpoint reloads, and faster MoE routing. Home fine-tune loop ~25% cheaper across the board.
ianlapham: the personal research engine pattern
@ianlapham · 877 likes · May 8
"Setting up a personal research engine is one of the highest-ROI things you can do." Concrete recipe: cloud-hosted agent (hermes / openclaw), memory layer (cognee), recurring ingestion jobs, retrieval skills. The harness layer is becoming the new personal OS for knowledge workers.
above_spec: "You don't need 24 GB VRAM for serious local LLMs"
@above_spec · 793 likes · May 1
"Just ran a 35B-parameter model on an RTX 4060 Ti 8 GB: 41 tok/s at 16k context, 24 tok/s at 200k context." MoE-offload to DDR5 + q8 KV cache on an 8 GB consumer GPU quietly resets the "you need a workstation" assumption from $1,500 to under $400.
Mistral Medium 3.5 vision-reasoning on 64 GB RAM
@UnslothAI · 688 likes · April 29
"Mistral-Medium-3.5-128B offers highly competitive performance for models 6x its size. Run locally on ~64GB RAM." First major Mistral vision-reasoning release in months at a size a 64 GB Mac can host.
Hugging Face launches the Reachy Mini robot app store
@ClementDelangue · 680 likes · May 6
"The agentic robotics app store. 300+ apps, 10,000 robots in the wild." First open-source robotics app store; apps generated by HF's ML Intern agent. NVIDIA Robotics piggybacked with Isaac GR00T integration the same day.
isaac_flath: "RLM is the foundation of my Pi Harness"
@isaac_flath · 655 likes · April 26
"Context as a Python variable, LLM as the programmer, REPL as the runtime." Recursive Language Model inside a Python REPL, seeded with late-interaction retrieval (pylate). Clean alternative to top-3/top-5 retrieve-then-stuff that small local models can drive without a frontier-tier context budget. (Pi here = the Pi agent harness, not Raspberry Pi.)
badlogicgames: the frontier-API regression complaint
@badlogicgames · 215 likes · May 7
Quoting antirez: "This is the best way to impair your LLM agent — make it blind in order to save prefill GPU time and KV cache size." The "frontier APIs are silently regressing on context handling" thread that pushed devs into local DS4 / DeepSeek V4 territory.
Closer: a DGX Spark writes its own CUDA kernels
@sudoingX · 151 likes · May 8
"My DGX Spark is writing custom CUDA kernels to make itself faster. Hermes agent running Qwen 27B Q8 autonomously decided to port its own Triton kernel to native CUDA C++ for llama.cpp integration." Auto-research + local model + small box = self-improving inference stack. The fortnight's most "this is real" demo.
See you next time.
The Model Interface
Subscribe: chetantekur.substack.com