
The Model Interface Edge Weekly — Issue 5
Week of Mar 8-14, 2026

Week of Mar 8-14, 2026 • Issue 5
📄 Papers
Agent Memory Below the Prompt: Persistent KV Cache for Edge Devices
Shkolnikov • arXiv
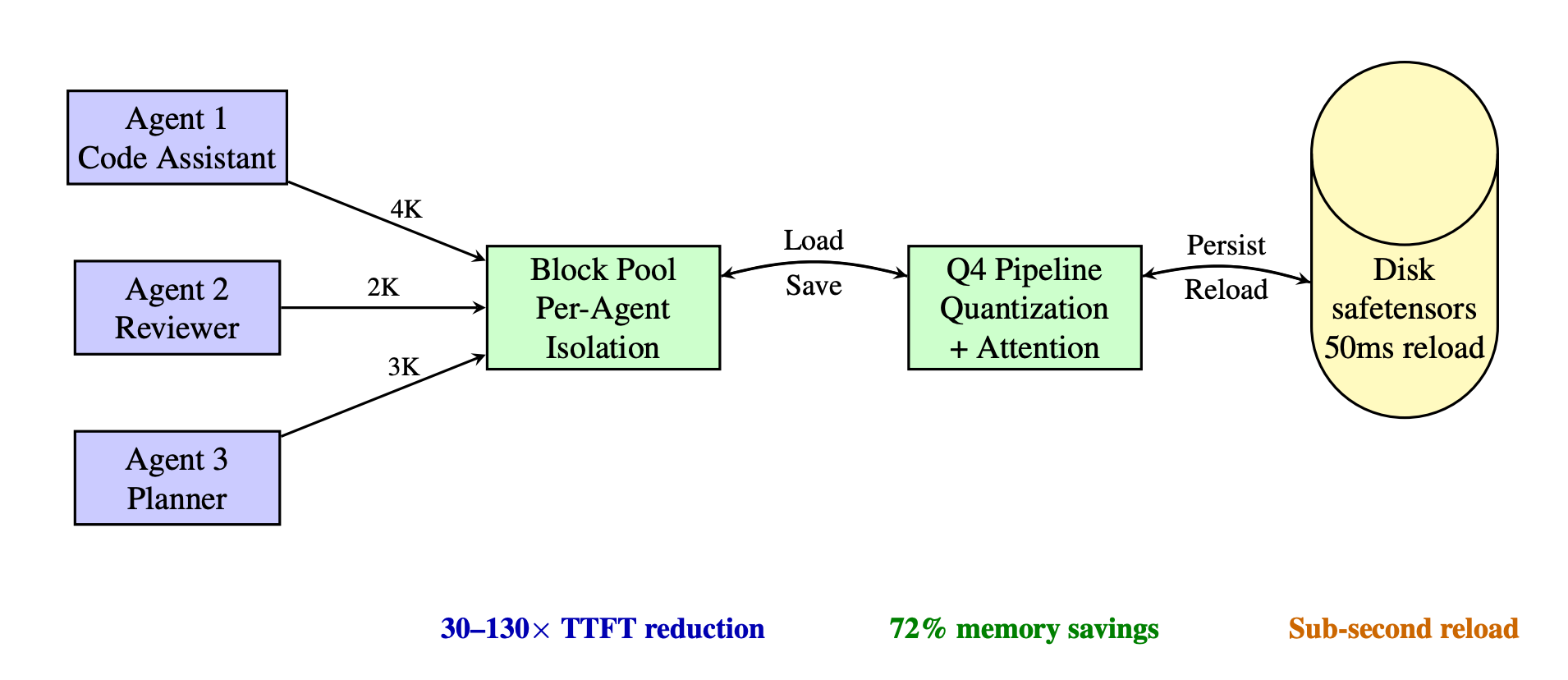
Multi-agent LLM systems on edge devices hit a hard memory wall. On an Apple M4 Pro with 10.2 GB of cache budget, only three agents fit at 8K context in FP16. This paper proposes persisting each agent's KV cache to disk in 4-bit quantized format and reloading it directly into the attention layer. That bypasses the expensive O(n) prefill recomputation entirely.
The trick is clever. Multi-agent systems naturally interleave. One agent generates while the next loads. The reload latency (around 500 ms) hides behind the previous agent's decode phase. Results on Gemma 3 12B, DeepSeek-Coder-V2-Lite 16B, and Llama 3.1 8B show cache restoration reduces time-to-first-token by up to 136x. Q4 quantization fits 12 agents into fixed device memory versus 3 with FP16. Perplexity degradation stays minimal: under 3% across all models tested.
Why it matters? Multi-agent systems are the next frontier for on-device AI, but memory is the hard constraint. This paper offers a practical, deployable solution that 4x the number of agents you can run on fixed hardware and reduces TTFT. If you're building multi-agent workflows on consumer devices, this is directly useful today.
Resource-Efficient NAS on a Single GPU
Gu et al. • arXiv
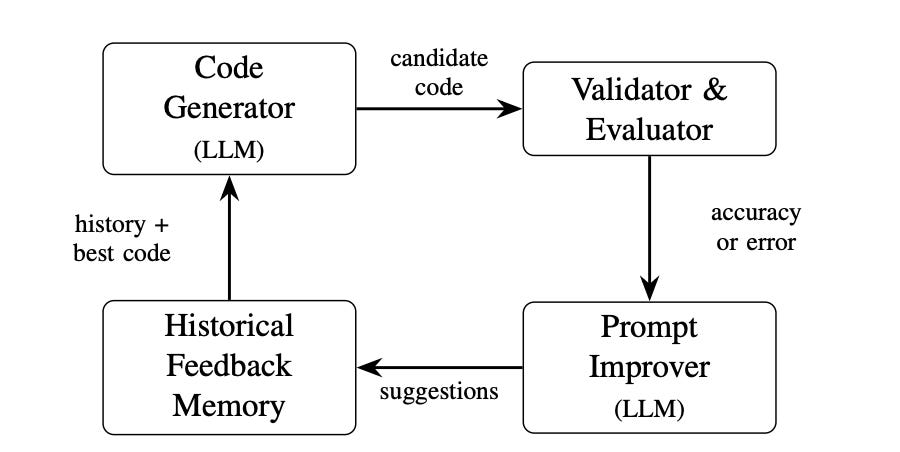
Researchers developed an LLM-driven Neural Architecture Search pipeline for a Convolutional Neural Network (CNN) that runs entirely on a single RTX 4090 GPU. The dual-LLM approach uses a Code Generator and Prompt Improver with historical feedback memory. From the paper: A full 2000-iteration search completes in ≈18 GPU hours on a single RTX 4090, establishing a low-budget, reproducible, and hardware-aware paradigm for LLM-driven NAS without cloud infrastructure.
The system implicitly favors compact, hardware-efficient models by sharing limited VRAM between the LLM and architecture training. This makes state-of-the-art NAS accessible without cloud infrastructure.
Why it matters? Democratizes neural architecture optimization for edge devices. You no longer need massive compute clusters to design efficient models or may be even domain expertise. Smaller CNNs, BERT, ASR are still used extensively on edge devices. Improving the efficiency and quality of these models are going to help with saving energy for the larger LLMs while also providing better user experience to the consumers.
Slow-Fast Inference: 14× Faster Decoding
Xie et al. • arXiv
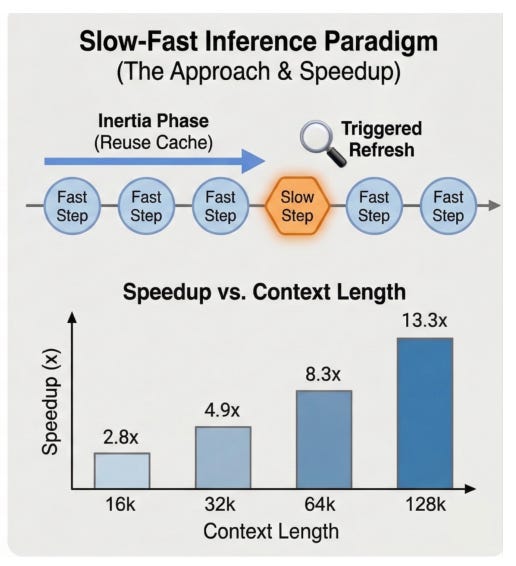
A new decoding framework decouples generation into frequent low-cost "fast steps" and occasional "slow steps" at semantic boundaries. It reuses compact sparse memory for most tokens and only runs full attention when needed.
The approach achieves 1.6× to 14.4× higher throughput while maintaining quality. It works by exploiting the observation that dominant attention support remains stable within short spans.
Why it matters? Training-free acceleration for long-context LLMs. This makes reasoning models practical for production and on-device deployments without model modifications. Faster and more efficient inference on the edge can unlock many new use cases.
📱 Smart Devices & Wearables
Samsung Reveals AI Smart Glasses at MWC 2026
Samsung officially shared the first details of its AI smart glasses on March 6. The first-generation device features an eye-level camera that feeds visual information to a connected Galaxy smartphone. The phone handles all AI processing and returns contextual information to the wearer.
Samsung's head of MX Business, JH Kim, explained the glasses will understand "where you're looking at" so they can "feed the information to the mobile phone and then it processes and actually gives you a lot of information." The glasses integrate Google's Gemini AI assistant for voice interactions and contextual help.
Samsung partnered with Gentle Monster and Warby Parker for the design. Qualcomm CEO Cristiano Amon confirmed to CNBC that the glasses will ship in 2026. This is Samsung's first entry into smart glasses and a direct challenge to Meta's Ray-Ban lineup.
The architecture is textbook distributed edge AI. Lightweight sensors on the face, heavy inference on the phone's NPU. Samsung is betting you already own the most powerful AI computer you need: your phone. This keeps the glasses light, affordable, and battery-efficient while still delivering real-time AI features.
Apple’s "Fusion Architecture": The New On-Device AI Powerhouse

The new M5 Pro and M5 Max are here, and from an Edge AI perspective, the numbers aren't just incremental—they’re a structural shift. Apple’s new Fusion Architecture effectively fuses two dies into a single SoC using advanced packaging. This isn't just about raw speed; it's about eliminating the "memory wall" that plagues multi-agent systems. By combining these dies, Apple is delivering 614GB/s of unified memory bandwidth on the M5 Max.
Why it matters? The inclusion of dedicated Neural Accelerators within each GPU core (scaling up to 40 cores) provides a massive 4x boost in peak AI compute, specifically enabling advanced, real-time workflows like on-device agentic coding in Xcode. This confirms a transition where the local machine isn't just a static tool, but a proactive partner. Furthermore, the introduction of industry-first Memory Integrity Enforcement ensures that these intensive local AI processes remain secure and private at the hardware level. This unique combination of massive shared VRAM and robust security solidifies the MacBook Pro's position as the premier workstation for the "local-first" movement, offering a portable alternative to data-center-dependent development. One of the upcoming Mac Studio with this chip will hopefully have my name on it. (Hope, my wife is not reading this)
NVIDIA N1/N1X ARM Laptop Chips: GTC 2026 Preview
NVIDIA is expected to unveil its N1 and N1X system-on-chips at GTC 2026 (March 16-19). Developed with MediaTek, these ARM-based SoCs integrate Blackwell graphics and next-gen Tensor cores directly onto an ARM CPU. The N1X reportedly features up to 20 CPU cores.
Dell and Lenovo are confirmed as initial OEM partners. First laptops expected in H1 2026. NVIDIA owning the entire stack (CPU, GPU, AI accelerator) on a single SoC is a fundamentally different approach from Qualcomm’s NPU add-on or Apple’s Neural Engine. If the N1X delivers integrated Blackwell-class AI acceleration in a laptop form factor, it could enable running larger language models locally than any competing architecture. This is NVIDIA bringing data center AI DNA to the laptop. Drool! We are going to be so spoiled.
Google Pixel March 2026 Feature Drop
Google Blog • Android Authority
The March 2026 Pixel Feature Drop rolled out on March 3 with a substantial set of on-device AI features.
Call Notes on Pixel 10 uses Gemini Nano to record calls, generate transcripts, and summarize conversations. All processing happens locally on the device. Scam Detection, also powered by Gemini Nano, expanded to six new countries: France, Italy, Spain, Mexico, Germany, and Japan. It uses on-device AI to detect malicious in-call speech patterns and alert users with verbal and haptic feedback.
New Gemini "task assistance" handles repetitive tasks in the background based on user commands. Think ordering groceries or booking a ride. Circle to Search gained multi-object image recognition. AI-generated custom icons let users redesign their homescreen in various styles (available on Pixel 6 and newer).
The geographic expansion of Scam Detection shows Gemini Nano scaling globally, not just as a US-first feature. On-device AI models are now mature enough for international deployment with language-specific tuning. The task assistance feature hints at on-device agentic AI coming to phones, where the model doesn't just answer questions but takes actions on your behalf.
Meta Ray-Ban Gets Hands-Free Accessibility
Meta announced hands-free Be My Eyes integration on March 11 at the CSUN Assistive Technology Conference. Users can now say "Hey Meta, Be My Eyes with [name]" to reach trusted contacts or service representatives from brands like Tesco, Sony, Hilton, and Amtrak for visual assistance.
The feature works completely hands-free. No phone needed.
This transforms smart glasses from tech toy to genuine assistive device. The killer app for smart glasses might be accessibility, not social media.
🏠 On-Device AI & Local Assistants
Ollama 0.17: One-Command Local AI Agents via OpenClaw
Phoronix • Ollama Blog • GitHub

Ollama 0.17 introduces native OpenClaw integration via ollama launch openclaw. One command handles installation, security notices, model selection, and launches a text UI. What previously required Docker compose files, environment variables, and manual configuration now takes a single line.
OpenClaw is an open-source personal AI agent that handles email, calendar, and task management through messaging platforms like WhatsApp, Telegram, and iMessage. With Ollama's integration, it runs entirely locally using open-weight models. No cloud API keys required.
The latest patch (v0.17.7, March 6) adds context length support for compaction when using ollama launch, improving memory management for long agent sessions. The v0.17.x line also adds MLX engine improvements and thinking level support for reasoning models.
Ollama has been the go-to runtime for local LLMs. This release marks its expansion from model serving into agent orchestration. The barrier for running a local AI agent that manages your email, calendar, and tasks just dropped from "weekend project" to "one command." No Docker, no API keys, no cloud.
🐦 Social Signals
Gemma-WebGPU: 1B Model in Browser, Zero Dependencies
Nikhil Thorat released gemma-webgpu: a zero-dependency, blazing fast Gemma 1B running entirely in the browser using WebGPU. No server. No API calls. No npm dependencies.
The implementation leverages WebGPU compute shaders for efficient inference directly in modern browsers. Users can run a billion-parameter model without installing anything.
Browser-based LLMs are reaching production quality. This democratizes access to AI without requiring users to have powerful local hardware or cloud accounts. Privacy-first by default.
Top 7 Local AI Models for Laptops in 2026
@hasantoxr • 229 likes
"Top 7 local AI models you can run on a laptop right now: 1. Qwen3 Coder 30B 2. Gemma 3n E4B 3. Magistral Small 1.2 4. Hermes 4 14B 5. Jan-Nano 6. LFM2-VL 1.6B 7. Qwen Image Edit. No API. No subscription. No data sent anywhere."
The breadth of local models in March 2026 is remarkable. Coding, vision, agentic tool use, image editing. All running without cloud dependencies on consumer hardware.
OpenClaw Memory Skill Hits 26k Users in One Week
@kevinnguyendn • 1,719 likes
"OpenClaw's memory system is broken by default. It requires curating massive MEMORY.md files or relying on duplicate-heavy generation. Hours are wasted tuning, and massive amounts of tokens are burned. So we built the memory skill to solve that."
The Memory Skill claims 92.19% accuracy after 8+ months of architecture iteration. Supports local and cloud storage with version control. 26k+ users in one week shows the demand for better agent memory management. This is the ecosystem growing around OpenClaw faster than anyone expected.
Google Announces MCP for Android via AppFunctions
@JorgeCastilloPr • 1,713 likes
"Google announces MCP for Android. AppFunctions lets Android apps expose capabilities directly to AI agents. Agents can discover and execute them via natural language. No app navigation needed."
MCP (Model Context Protocol) on Android means AI agents can interact with apps natively instead of screen-scraping or custom APIs. Google is building the plumbing for on-device agentic workflows directly into the OS. Every Android app becomes a potential tool for an AI agent.
Liquid AI LocalCowork: 67 Tools, Zero Network Calls
@liquidai • 1,544 likes
"385ms average tool selection. 67 tools across 13 MCP servers. 14.5GB memory footprint. Zero network calls. LocalCowork is an AI agent that runs on a MacBook. Open source."
An AI agent orchestrating 67 tools across 13 MCP servers, all running locally on a MacBook with sub-400ms response times. This is proof that the local AI agent stack is production-ready for power users. The 14.5 GB footprint fits comfortably on any modern laptop.
Autoresearch: Automated Training Loops for Small Language Models
@_philschmid • 186 likes
"What if you could optimize a model overnight without any ML experience? What if an AI agent runs hundreds of training experiments autonomously, keeping only the improvements? That is the idea behind autoresearch."
Early results show a 0.8B model beating a 1.6B after automated optimization. The implications for edge deployment are significant: smaller models that outperform larger ones means better on-device inference with less memory and power.
RCLI + MetalRT: Fastest On-Device Voice AI for macOS
@sanchitmonga22 • 78 likes
"Launching RCLI + MetalRT: the FASTEST on-device voice AI for macOS. 658 tok/s LLM decode (1.19x > MLX). 714x real-time STT (4.6x > MLX Whisper). 8.8x RTF TTS (2.8x > MLX Audio). 63ms voice-to-audio latency."
RunAnywhere's MetalRT engine beats every existing inference engine on Apple Silicon, including MLX, llama.cpp, and sherpa-onnx. 36 macOS actions (open apps, web search, control Spotify), all local, offline, open-source. The 63ms voice-to-audio latency makes real-time voice interaction genuinely seamless.
Gemini Embedding 2: First Natively Multimodal Embedding Model
@WesRoth • 119 likes
"Google has just released Gemini Embedding 2, its first natively multimodal embedding model. It maps text, images, video (up to 120s), audio, and PDFs into a single unified embedding space."
A single embedding space for text, images, video, and audio means cross-modal search becomes trivial. Search for "the sound of a busy street" and find matching videos, photos, and audio recordings. The edge AI angle: once multimodal embeddings are small enough for on-device RAG, local search gets dramatically more powerful.
8 Local LLMs Benchmarked on DGX Spark
"I benchmarked 8 local LLMs on DGX Spark. It's not China vs. USA — it's Qwen vs. everyone."
Real-world performance comparison showing Qwen models dominating across multiple tasks. The gap between Qwen and other open models continues widening. Validates what we've been seeing: Qwen's edge AI optimization work is paying off.
ByteDance Open Sources AI Agent "Brain"
ByteDance just open sourced a "brain" for AI agents. Enables agents to maintain long-term memory, learn from interactions, and improve decision-making over time.
Moves beyond stateless agents to persistent, learning systems. Could be a major unlock for on-device agents that need to adapt to user preferences without cloud sync.
See you next week.
— The Model Interface